Met de opkomst van AI coding agents zoals Kiro, Cursor en Claude Code verscheen er weer een nieuw ‘patroon’ aan de horizon: Spec Driven Development (SDD). Het idee: schrijf eerst een gedetailleerde specificatie, laat de AI de code genereren, en itereer tot de tests slagen. Klinkt efficiënt. Maar riekt dit niet verdacht veel naar… waterval?
Birgitta Böckeler, Distinguished Engineer bij Thoughtworks, onderzocht dit fenomeen in een serie artikelen op Martin Fowler’s blog (Böckeler, 2025). Ze identificeert drie niveaus van SDD, van pragmatisch tot puriteins. In dit artikel bespreek ik haar analyse, de parallellen met eerdere “silver bullets”, en waarom de Thinkism... read more
Met de opkomst van AI coding agents zoals Kiro, Cursor en Claude Code verscheen er weer een nieuw ‘patroon’ aan de horizon: Spec Driven Development (SDD). Het idee: schrijf eerst een gedetailleerde specificatie, laat de AI de code genereren, en itereer tot de tests slagen. Klinkt efficiënt. Maar riekt dit niet verdacht veel naar… waterval?
Birgitta Böckeler, Distinguished Engineer bij Thoughtworks, onderzocht dit fenomeen in een serie artikelen op Martin Fowler’s blog (Böckeler, 2025). Ze identificeert drie niveaus van SDD, van pragmatisch tot puriteins. In dit artikel bespreek ik haar analyse, de parallellen met eerdere “silver bullets”, en waarom de Thinkism Fallacy hier relevant is.
Sectie 1 beschrijft de drie niveaus van SDD. Sectie 2 trekt de parallel met eerdere pogingen om specificaties tot broncode te verheffen. Sectie 3 introduceert de Thinkism Fallacy als kritisch kader. Sectie 4 nuanceert: wanneer werkt SDD wél? Sectie 5 sluit af met de vraag hoe dit zich verhoudt tot onze eigen praktijk.
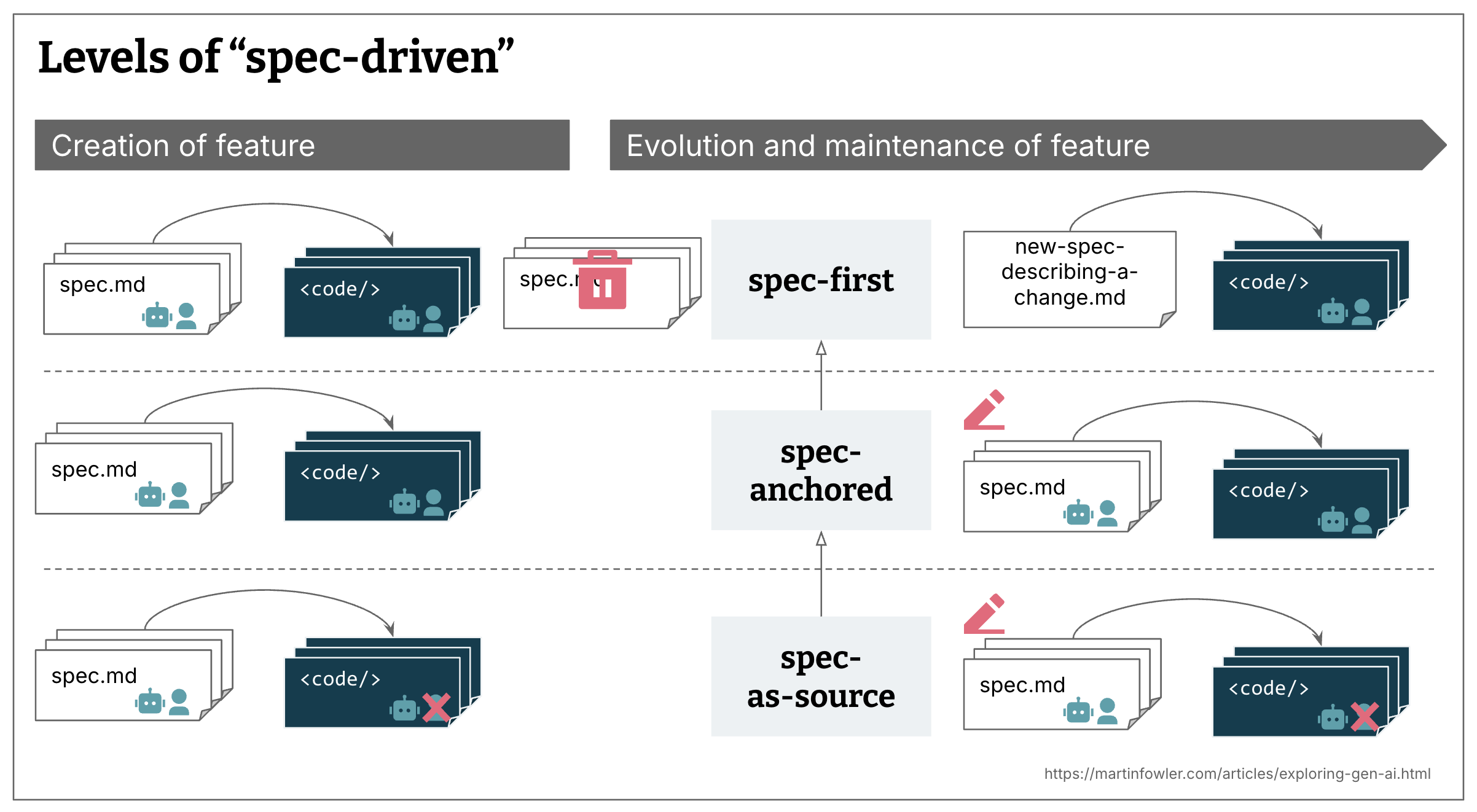
1. De drie niveaus van Spec Driven Development
Böckeler onderscheidt drie manieren waarop teams specificaties gebruiken in combinatie met AI:
Figuur 1: De drie niveaus van SDD: spec-first, spec-anchored en spec-as-source. Bron: Böckeler (2025) via martinfowler.com.
Kanttekening: Het diagram suggereert dat spec-as-source het “hoogste” niveau is, maar ik betwijfel of dat wenselijk is. Puur top-down werken — elke keer de spec aanpassen en de AI opnieuw laten genereren — negeert de waarde van iteratie tijdens het bouwen. Het doet denken aan de chaostheorie: kleine, nauwelijks merkbare wijzigingen in een spec kunnen grote effecten hebben in de gegenereerde code (het vlindereffect). Een mix van top-down (spec) en bottom-up (iteratie op code) lijkt me robuuster dan blind vertrouwen op spec-as-source.
Figuur 2: Het vlindereffect toegepast op specs: een kleine wijziging in de specificatie kan onvoorspelbare gevolgen hebben in de gegenereerde code.
1.1 Spec-first
Bij spec-first schrijf je een uitgebreide specificatie vóórdat je begint met coderen. De AI gebruikt deze spec om code te genereren. Na voltooiing van de feature verdwijnt de spec — het was een wegwerp-artefact om de AI te sturen.
Dit is vergelijkbaar met hoe je een goede prompt schrijft: context geven, verwachtingen uitspreken, en dan de AI laten draaien.
1.2 Spec-anchored
Spec-anchored gaat een stap verder: de specificatie blijft bestaan na oplevering. Bij wijzigingen update je eerst de spec, dan de code. De spec fungeert als levende documentatie die synchroon loopt met de implementatie.
1.3 Spec-as-source
Het meest ambitieuze niveau: de specificatie is de broncode. Mensen bewerken alleen de spec, nooit de gegenereerde code (die bevat “DO NOT EDIT” commentaar). De AI vertaalt specs naar werkende software.
Dit is de droom die we eerder zagen bij UML-als-broncode, Model-Driven Development, en low-code platforms.
2. De déjà vu van “spec als broncode”
Spec-as-source is de zoveelste iteratie van een oud idee: als we de specificatie maar formeel genoeg maken, kunnen we de implementatie automatisch afleiden.
We zagen dit bij:
UML round-tripping (jaren ‘90-‘00): Genereer code uit UML diagrammen, en vice versa
Model-Driven Architecture (MDA): Platform-onafhankelijke modellen die naar code transformeren
Executable specifications: BDD tools zoals Cucumber die “living documentation” beloven
Geen van deze benaderingen werd mainstream voor algemeen softwareontwikkeling. Waarom niet? Böckeler noemt het kernprobleem: “één workflow voor alle maten” werkt niet. Kleine bugs vereisen geen 47 markdown bestanden om te reviewen.
3. De Thinkism Fallacy
Kevin Kelly introduceerde het concept Thinkism: de misvatting dat problemen opgelost kunnen worden door puur meer intelligentie (Kelly, 2017). Een superintelligentie kan niet in één dag kernfusie uitvinden zonder experimenten. Sommige kennis vereist tijd en interactie met de werkelijkheid.
Dit is relevant voor SDD. De impliciete aanname is: als we de specificatie maar goed genoeg formuleren, en de AI maar slim genoeg is, dan volgt correcte code automatisch. Maar software ontwikkeling is geen deductief probleem. Het is een ontdekkingsreis waarbij we door te bouwen leren wat we eigenlijk wilden bouwen.
De ironie: SDD probeert de “messy” iteratieve realiteit van softwareontwikkeling te omzeilen door vooraf alles uit te denken. Dat is precies de waterval-denkfout.
4. Wanneer werkt SDD wél?
Nu de nuance. SDD is niet per definitie slecht. Er zijn scenario’s waarin een spec-first aanpak zinvol is:
Greenfield met duidelijke requirements: Als je precies weet wat je wilt, kan een spec de AI effectief sturen
Geïsoleerde features: Nieuwe functionaliteit zonder veel bestaande code-interacties
Proof of concepts: Snel iets werkend krijgen om te valideren
Böckeler’s kritiek richt zich vooral op spec-as-source als universele werkwijze. Voor complexe brownfield situaties — bestaande codebases met subtiele afhankelijkheden — is de spec vaak incomplete of zelfs misleidend.
5. En ons eigen SRS document dan?
Voor ons als opleiding is er nog een praktische complicatie: wij gebruiken de afkorting SDD al voor Software Design Document. We hebben hier te maken met een homo(acro)nym — een acroniem dat dezelfde letters heeft maar iets heel anders betekent. Een homonym is de tegenhanger van een synoniem: waar een synoniem twee verschillende woorden zijn met dezelfde betekenis, is een homonym hetzelfde woord met verschillende betekenissen. En een acroniem is een afkorting waarbij elke letter uitklapt naar een woord (dus “etc.” is geen acroniem, maar “SDD” wel).
Ons SRS (Software Requirements Specification) document lijkt ook verdacht veel op wat in Spec Driven Development de “spec” heet. Betekent dit dat we al jaren onbewust SDD doen? Niet helemaal. Bij AIM was het SRS bedoeld als communicatiemiddel met de opdrachtgever, én als basis voor het Software Design Document — het ontwerp en de beschrijving van de uitwerking. In de praktijk vonden studenten het lastig om de consistentie tussen deze documenten te bewaken. Vaak werd het SRS met terugwerkende kracht afgeleid uit de implementatie, waardoor het meer “documentatie” werd dan “ontwerp”.
Zou ons SRS bruikbaar zijn als AI-spec? Hier stuiten we op een fundamenteel probleem. In een eerdere blogpost over Prompt Engineering (Van der Wal, 2024) haalde ik Dijkstra aan over “the foolishness of natural language programming”. Natuurlijke taal is inherent ambigu. Een mens kan die ambiguïteit vaak oplossen door context en gezond verstand, maar dat veronderstelt gedeelde kennis die niet in het document staat.
AI kan beter worden in het interpreteren van menselijke documenten, maar de fundamentele ambiguïteit blijft. Een SRS dat voor mensen helder is, kan voor een AI nog steeds meerdere interpretaties hebben. De vraag is niet alleen óf we ons SRS als AI-spec willen gebruiken, maar of dat überhaupt kan zonder de specificatie zo formeel te maken dat het geen natuurlijke taal meer is.
Bronnen
Böckeler, B. (januari 2025). Spec-driven development (SDD): Tools. Geraadpleegd van https://martinfowler.com/articles/exploring-gen-ai/sdd-3-tools.html
Kelly, K. (oktober 2017). The Thinkism Fallacy. Geraadpleegd van https://kk.org/thetechnium/the-thinkism-fallacy/
Van der Wal, B. (december 2024). Prompt Engineering. Geraadpleegd van https://bartvanderwal.nl/prompt-engineering/
Bart van der Wal
Docent aan de HAN University of Applied Sciences en MAMIL met een passie voor SwimRun en andere avontuurlijke duursportavonturen. Schrijft over technologie, softwareontwikkeling en duursport.

 Figuur 1: De drie niveaus van SDD: spec-first, spec-anchored en spec-as-source. Bron: Böckeler (2025) via martinfowler.com.
Figuur 1: De drie niveaus van SDD: spec-first, spec-anchored en spec-as-source. Bron: Böckeler (2025) via martinfowler.com. Figuur 2: Het vlindereffect toegepast op specs: een kleine wijziging in de specificatie kan onvoorspelbare gevolgen hebben in de gegenereerde code.
Figuur 2: Het vlindereffect toegepast op specs: een kleine wijziging in de specificatie kan onvoorspelbare gevolgen hebben in de gegenereerde code.