Oordeelsvorming: Taxonomie van AI-gebruik - wie heeft de regie?
Leestijd: 29 minuten
In dit drieluik verken ik hoe ICT-onderwijs moet veranderen met de komst van AI. Dit tweede deel gaat over oordeelsvorming: een taxonomie van AI-gebruikstypes om te onderscheiden van wie ideeen komen, en wie de regie heeft; mens of AI?
Drieluik structuur (BOB-model):
Blog 1/3 (Bewustwording): De komst van AI en evolutie van interactiemodi (Conversational, Inline, Agentic)
Blog 2/3 (Oordeelsvorming): Taxonomie van AI-gebruik: wie heeft de regie? - deze blog
Blog 3/3 (Besluitvorming): AI als leermiddel, niet als butler
Over interactiemodi en gebruikstypes: In blog 1/3 introduceerde ik drie interactiemodi: Conversational, Inline, en Agentic. Die beschrijven de technische interface en workflow. Deze... read more
Oordeelsvorming: Taxonomie van AI-gebruik - wie heeft de regie?
Leestijd: 29 minuten
▶Versiegeschiedenis
Datum
Status
Toelichting
12 jan 2026
Gestart
Eerste idee
20 jan 2026
Gepubliceerd
Eerste publicatie
21 jan 2026
Gewijzigd
Sectienummers en leeswijzers toegevoegd voor beter lezernavigatie en structuur. Hoofd-leeswijzer in inleiding uitlegt het hele verhaal; mini-leeswijzers bij secties met subsecties geven kort preview conform Pyramid Principle. Subsectienummering (x.y format) toegevoegd als verwijzingsreferentie.
21 jan 2026
Gewijzigd
Citatienormalisatie (Yang et al.→Yang); Figuur 3 Michael Feathers quote caption; back-link naar blog 3 (Besluitvorming)
In dit drieluik verken ik hoe ICT-onderwijs moet veranderen met de komst van AI. Dit tweede deel gaat over oordeelsvorming: een taxonomie van AI-gebruikstypes om te onderscheiden van wie ideeen komen, en wie de regie heeft; mens of AI?
Drieluik structuur (BOB-model):
Blog 1/3 (Bewustwording): De komst van AI en evolutie van interactiemodi (Conversational, Inline, Agentic)
Blog 2/3 (Oordeelsvorming): Taxonomie van AI-gebruik: wie heeft de regie? - deze blog
Blog 3/3 (Besluitvorming): AI als leermiddel, niet als butler
Over interactiemodi en gebruikstypes: In blog 1/3 introduceerde ik drie interactiemodi: Conversational, Inline, en Agentic. Die beschrijven de technische interface en workflow. Deze blog gaat over gebruikstypes: Human in the Lead, Human Curates, AI in the Lead, en Old Skool. Die beschrijven de intentie en werkwijze. Dit zijn dus verschillende dingen, maar er zijn wel correlaties tussen beide (zie sectie 2.1).
Stel je voor: ICT-student Amad zegt in een gesprek “Ik heb AI gebruikt.”
Scenario A: Stage bij een ICT-bedrijf. De student zit tegenover zijn bedrijfsbegeleider tijdens zijn stage. Elke developer én stagiair heeft een betaald Claude-abonnement. De begeleider knikt goedkeurend: “Mooi, daarom hebben we je die toegang gegeven. Domme code uittypen hoef je niet zelf te doen.”
Scenario B: Essay voor school. Dezelfde student zit tegenover zijn docent Professional Skills die AI heeft verboden. De docent fronst: “Dat mag niet. Je moet alles zelf schrijven.” De student had zijn AI gebruik ook kunnen verzwijgen - het is moeilijk, zo niet onmogelijk om te controleren.
Twee gesprekken, dezelfde woorden, tegenovergestelde reacties. Maar hier wordt het interessant. Ook de bedrijfsbegeleider wil NIET dat de stagiair klakkeloos AI output overneemt. En ook de docent zou het prima vinden als de student AI gebruikt om feedback te krijgen op zelf geschreven tekst - mits de student alles controleert en in het proces leert. De reactie hangt niet af van of je AI gebruikt, maar hoe.
Figuur 1: De vier types AI-gebruik (met Type 4 opgesplitst in drie varianten): van menselijk idee met AI-generatie tot mens zonder AI
Een taxonomie is een systematische classificatie, waarbij je dingen kunt onderverdelen, typisch in een verdeling waarbij elk item maar in categorie hoort. In deze AI-gebruik taxonomie stel ik onderverdeling van AI-gebruikstypes. Dit is een kwadrant met twee dimensies: wie verzint het idee mens of AI en wie is in de lead mens of AI.
Deze blog begint met een beschrijving van de vier hoofdtypes en hun zeven varianten, waarbij ik de kwadranten één voor één langslopen. Vervolgens laat ik zien hoe deze types in de praktijk door elkaar lopen en niet strikt gescheiden zijn. Dan introduceer ik het concept van prompt/answer asymmetry: hoe de lengte van je vraag en het antwoord omgekeerd evenredig kunnen zijn. De naamgeving van deze types komt daarna aan bod, inclusief waarom betere namen dan “Type 1, 2, 3, 4” belangrijk zijn, en hoe constraints essentieel zijn voor verantwoord AI-gebruik. Tot slot bespreek ik de exploratieve modus: wanneer experts tijdelijk als beginners leren. Ik sluit af met een conclusie over Guitar Hero en leren, en een discussie over transparantie.
1. De vier AI-gebruikstypes
We lopen de vier kwadranten langs, met twee assen: wie heeft het idee, en wie heeft de lead? Bij het vierde kwadrant blijkt onderverdeling nuttig.
1.1 Type 1: Human in the Lead
De mens heeft het idee en formuleert dit in een gedetailleerde eerste prompt — een soort specificatie van een probleem of eigen idee. De AI genereert op basis daarvan. De cyclus gaat verder met menselijke input en sturing.
Dit is hoe ik deze blog schrijf. Ik heb een onderwerp, een standpunt, specifieke voorbeelden die ik wil gebruiken. De AI helpt formuleren, structureren, bronnen checken. Maar de richting komt van mij.
Het principe: één prompt is geen prompt. Je itereert, stuurt bij, verwerpt suggesties, vraagt om alternatieven. De AI is een tool, geen auteur.
Je zou kunnen stellen dat een vraag om ideeën (Type 2) zelf ook een idee is. Maar het verschil zit in de mate van detail. Bij Type 1 bevat de eerste prompt al veel context en richting.
1.2 Type 2: Human Curates
De mens vraagt de AI om ideeën te genereren — een korte, open vraag. De mens maakt vervolgens een serieuze keuze welke richting te volgen. Verdere stappen kunnen weer met AI, maar met bewuste menselijke input.
Voorbeeld: “Geef me vijf mogelijke invalshoeken voor een blog over remote werken.” De mens kiest er één, en werkt die uit — mogelijk weer met AI-hulp, maar met eigen toevoegingen en richtinggevoel.
Het verschil met Type 1: de eerste prompt is kort en open, niet gedetailleerd en richtinggevend. Het verschil met Type 3: de mens doet meer dan alleen “ja” zeggen.
1.3 Type 3: AI in the Lead
De mens vraagt AI om ideeën én om deze zelf uit te werken. Zonder serieuze tussenkomst: deze accepteert de voorgestelde voorkeurskeuze, of geeft door AI voorgelegde opties weer aan de AI terug (“wat zou jij doen?” of “kijk maar”).
Figuur 2: “Create apps without knowing how to code” klinkt verleidelijk, maar levert geen begrip op
Dit is de valkuil van “vibe coding” zonder ervaring: de AI genereert, de mens klikt op “accept”, en niemand weet meer precies wat er in de code staat of waarom.
Het resultaat kan technisch werken, maar de mens heeft geen grip op wat er is gemaakt of hoe het te onderhouden.
1.4 Type 4: Mens zonder AI
Dan het vierde type. Je zou kunnen stellen dat dit geen AI-type is, omdat we bij het langsgaan van de kwadranten nu logisch uitkomen bij ‘mens doet alles’. Maar ik doe het tegenovergestelde; ik splits deze op in drie subtypes.
1.5 4a. Old Skool
Pure menselijke arbeid, zoals we het decennialang hebben gedaan. Geen AI-tool geopend, geen assistentie gevraagd. De klassieke manier van werken.
Dit is geen nostalgische terugblik. Voor veel taken blijft dit de snelste en beste aanpak. Een goede developer typt soms gewoon code, zonder eerst een AI te raadplegen. Een schrijver schrijft, een ontwerper ontwerpt. Soms zegt Claude code of andere tool ook: ‘Je tokens zijn op., je kunt na 3 PM vanmiddag weer verder’. Of ze zijn zelfs op voor de maand; maar je bedenkt je dat je die wijziging ook prima zelf kunt doen.
1.6 4b. Rubber Duck AI: AI als klankbord
Je legt je probleem uit aan een collega, en tijdens het uitleggen bedenk je zelf de oplossing. Je had net zo goed tegen een badeend kunnen gaan praten.
De naam refereert aan rubber duck debugging: “a method of debugging code by articulating its problems in speech, commonly to an inanimate object such as a rubber duck” (Wikipedia, 2024).
Met AI werkt dit ook. Je begint een vraag te typen, en tijdens het formuleren realiseer je je het antwoord al. Of zelfs: je leest het AI-antwoord, beseft dat het nergens op slaat, en gaat je eigen weg — maar de noodzaak om je gedachtenproces uit te typen, of te formuleren heeft je geholpen.
Het interessante: de AI heeft geen inhoudelijke bijdrage geleverd. Het enige dat de AI deed was er zijn, als gesprekspartner. De motivatie komt van het gesprek zelf, niet van de output. Je zou kunnen zeggen dat je de AI antropomorfiseert — je behandelt het als gesprekspartner, terwijl het geen persoon is.
1.7 4c. Learned from AI: Geleerde kennis toepassen
Je hebt in het verleden AI gebruikt om iets te leren. Nu pas je die kennis toe — zonder AI te raadplegen. ‘AI as teacher’.
Voorbeeld: je hebt Claude gevraagd hoe een specifiek designpatroon werkt. Je las de uitleg, begreep het, en schreef het zelf over. Later gebruik je dat patroon opnieuw, uit je hoofd, zonder terug te gaan naar de AI.
Dit is relevant voor digitale examens. Als een student iets heeft geleerd met behulp van AI, en het vervolgens zelfstandig kan toepassen op het examen (zonder AI-toegang), dan is dat legitiem gebruik. Het onderscheid met spieken: de kennis zit in je hoofd, niet in de tool.
Natuurlijk kun je niet bewijzen dat iemand iets via AI heeft geleerd versus via een leerboek. Maar dat maakt ook niet uit — het punt is dat de kennis is overgedragen en begrepen.
Figuur 3: De vier AI-gebruikstypes in een kwadrant
2. In de praktijk lopen types door elkaar
In de praktijk gebruik je deze types door elkaar. Een sessie kan beginnen als Type 1, tijdelijk naar Type 2 gaan voor brainstormen, en eindigen in Type 4b (Rubber Duck AI) wanneer het AI-gesprek je doet realiseren dat je een bepaald stuk anders wilt aanpakken, en de AI bv. vast zit in een bepaald spoor. If zelfs Type 4a (Old Skool) wanneer je besluit een bepaald stuk helemaal zonder AI te doen.
Het punt is niet om strikt in één type te blijven. Het punt is om bewust te zijn van welk type je gebruikt en of dat past bij wat je wilt bereiken.
2.1 Correlatie met interactiemodi uit blog 1/3
De gebruikstypes in deze blog correleren met de interactiemodi (Conversational, Inline, Agentic) uit blog 1/3:
Human in the Lead werkt met alle drie de interactiemodi, maar vereist altijd constraints — ongeacht de modus
Human Curates gebruikt vaak Conversational AI om opties te brainstormen
AI in the Lead (Vibe Coding) — het risico is het grootst bij Agentic AI: volledige context + schrijfrechten + minimale inspanning = maximaal gevaar om controle te verliezen
Old Skool gebruikt geen van de drie interactiemodi
Het verschil: interactiemodi beschrijven de technische interface, gebruikstypes beschrijven de intentie en werkwijze. Maar hoe meer context en schrijfrechten de AI heeft, en hoe minder bewuste inspanning de mens levert, hoe groter het risico om onbewust in “AI in the Lead” te belanden.
3. Prompt/answer length asymmetry
Een interessant patroon dat hieruit volgt: de lengte van je prompt en de lengte van het antwoord zijn vaak omgekeerd evenredig.
Een korte, open prompt (“Schrijf iets over AI”) geeft de LLM weinig constraints. Het antwoord wordt lang en breed — de AI vult de ruimte die je laat.
Een lange, gedetailleerde prompt (“Schrijf een paragraaf over de ethische implicaties van gezichtsherkenning in openbare ruimtes, focus op de Nederlandse context, in actieve schrijfstijl. Noem twee concrete voorbeelden.”) geeft veel constraints. Het antwoord wordt specifieker en meer gefocust — de AI weet beter wat je wilt en vult minder zelf in.
Dit AI prompt/answer length asymmetry principe verklaart deels het verschil tussen Type 1 en Type 2. Bij Type 1 schrijf je lange, gedetailleerde prompts en krijg je gerichte antwoorden. Bij Type 2 schrijf je korte vragen en krijg je uitgebreide optielijsten.
Geen van beide is beter. Het hangt af van wat je nodig hebt: exploratie of executie.
Figuur 4: Prompt/answer length asymmetry
Disclaimer: Deze asymmetry die Figuur 2 tracht te schetsen is voorlopig nog even een hypothese, maar ik heb dit nog niet met praktisch onderzoek laten zien, of aangetoond buiten n=1. Sowieso is de ‘short question, broader answer’ en ‘long question, more specific answer’ relatie makkelijker hard te maken is, omdat het min of meer per definitie al geldt (gegeven een LLM die goed of in ieder geval geloofwaardig antwoord probeert te geven; wat ze doen). Voor het ‘long question, short answer’, ‘short question, long answer’ relatie heb ik nog onvoldoende tijd genomen dit ook proefonderlijk aan te tonen.
4. Betere namen dan “Type 1, 2, 3, 4”
Phil Karlton’s beroemde uitspraak luidt: “There are only two hard things in Computer Science: cache invalidation and naming things.” Goede naamgeving is moeilijk, maar wel belangrijk!
De volgende vier subsecties (4.1-4.4) behandelen hoe deze naamgeving tot stand kwam, wat “in the Lead” betekent voor eindverantwoordelijkheid, de spanning tussen upskilling en deskilling, en hoe constraints als vangnet werken.
Daniel Kahneman introduceerde in Thinking, Fast and Slow de termen “System 1” en “System 2” voor twee vormen van menselijk denken (Kahneman, 2011). Dit is een indrukwekkend stukje theorie en achtergrond, maar zijn namen zijn om te huilen! Enkel op de kracht van de theorie zijn deze — van zichzelf nietszeggende nummers — gemeengoed geworden, en weten velen wat type 1 en type 2 thinking is.
In de naamgeving Type X, type Y is wellicht een voordeel dat je laat zien dat het echt verschillende types zijn, en bv. niet een schaal van langzaam naar snel denken.
Figuur 5: “5 tomatoes” (five-two-eight-oh) om 5280 feet in a mile te onthouden vs. 1 km = 1000 m
Maar zulke getallen noemen we in software code ‘magic numbers’. En het onthouden van mapping (1=traag, onbewust en 2=snel, bewust) schaar ik zelf onder het kopje ‘accidental complexity’. Andere voorbeelden hiervan is het onhandige ‘Imperial system’ dat Engeland en de VS hanteren (met willekeurige eenheden), of numerieke systemen zonder duidelijke mnemonic (denk aan de meme “5 tomatoes” om 5280 feet in a mile te onthouden (Reddit, 2022) ).
Termen zonder intrinsieke betekenis zoals “System 1” of “Type X” — terwijl “Fast Thinking” en “Slow Thinking” — of beter nog “Intuitive” en “Deliberate” — zoveel begrijpelijker waren geweest. De ondertitel van Kahneman’s boek was letterlijk beschrijvender dan de termen zelf. Barbara Minto hamert in The Pyramid Principle op top-down helderheid: begin met de kern en gebruik namen die meteen duidelijk maken wat je bedoelt (Minto, 1987).
Roland Barthes introduceerde het concept “death of the author”: de betekenis van een tekst moet niet afhangen van kennis over de auteur of diens intenties (Barthes, 1967). Toegepast op naamgeving: een goede term moet zichzelf uitleggen. Je zou niet de originele bron moeten raadplegen om te begrijpen wat “System 1” betekent.
Met dat in gedachten: mijn namen voor de vier types.
Type
Naam
Wie stuurt?
1
Human in the Lead
Mens bepaalt richting én heeft eindregie
2
Human Curates
Mens selecteert uit AI-opties
3
AI in the Lead
AI bepaalt, mens accepteert
4a
Old Skool
Mens alleen, geen AI
4b
Rubber Duck AI
AI als denkpartner, geen inhoudelijke input
4c
Learned from AI
Mens past eerder geleerde AI-kennis zelfstandig toe
4.1 Meta: hoe deze naamgeving tot stand kwam
Deze blog is zelf een voorbeeld van Type 1 (Human in the Lead). Ik had initiële namen bedacht, en wilde de AI vragen of hij betere namen wist. Dit is echter een beetje een open vraag, en bovendien merk ik ook regelmatig dat de AI dan richtingen in gaat die ik echt niet wil. En dan ben je vaak langer bezig om alles te lezen, door te prompten of moet je alsnog alles schrijven (deze zin ben ik nu bijvoorbeeld ook zelf aan het schrijven, meest overige stukken schreef Claude op basis van mijn ideeen/prompts, maar de inleiding moet nog herschreven, want daar wil Claude het maar niet doen zoals ik een beetje in mijn hoofd heb.
In ieder geval gaf ik Claude nu dan de vraag om de huidige namen te beoordelen op basis van onderstaande vijf criteria, en om op basis van die feedback zelf met betere namen voor te stellen:
A. Begrijpelijkheid; ook volgens het ‘death of the author principe’
B. Interne consistentie van de namen
C. Uniekheid, is de term ‘googlebaar’
D. Goed onthoudbaar door mensen, kort genoeg maar ook interessant”
waarbij criterium B (interne consistentie van de namen) onderdeel van ‘conceptual integrity’, een van de belangrijkste quality attributes van een code base volgens Frederick Brooks in het klassieke boek ‘The Mythical Man-Month’ (Brooks, 1975).
Claude stelde alternatieve namen voor:
Type
Mijn naam
Alternatieve naam (AI)
1
Human in the Lead
Human Leads
2
Human Curates
—
3
AI in the Lead
AI Slop
4a
Old Skool
Human Solo
4b
Rubber Duck AI
—
4c
Learned from AI
—
Maar deze auteur is nog niet dead — ik hanteer gewoon mijn initiële namen. De AI mag suggereren, ik beslis.
“AI Slop” voor Type 3 is wel een treffende informele naam, refererend aan het woord van het jaar 2025: “slop” — AI-gegenereerde content zonder menselijke kwaliteitscontrole.
Naast de bovenstaande namen zijn er ook alternatieve benamingen die de werkwijze beschrijven:
Type
Naam
Development-stijl naam
1
Human in the Lead
Spec-Driven Development
2
Human Curates
Option-Driven Development
3
AI in the Lead
Vibe Coding
4a
Old Skool
Traditional Development
4b
Rubber Duck AI
Conversational Development
4c
Learned from AI
Knowledge-Transfer Development
Spec-Driven Development voor Type 1 verwijst naar het geven van een gedetailleerde specificatie (de prompt) waaruit de AI moet genereren. Net zoals bij traditionele spec-driven development begin je met een duidelijk document dat beschrijft wat er moet gebeuren.
Deze term komt uit het artikel Specification-Driven Development with GenAI Tools op Martin Fowler’s website (Harrer & Ford, 2024). Interessant genoeg is dit artikel uit oktober 2024 — midden in de AI-hype — en benadrukt het het belang van specificaties schrijven voordat je code genereert.
Dit idee krijgt inmiddels concrete tooling. Kiro (2025) is een “agentic IDE” die spec-driven development als kernprincipe hanteert. In plaats van direct te coderen op basis van vage prompts, genereert Kiro eerst gestructureerde requirements (in EARS-notatie), dan architectuurvoorstellen, en pas daarna implementatietaken — elk gekoppeld aan specifieke requirements. Het is het tegenovergestelde van vibe coding: expliciete documentatie vóór code.
Dit roept een interessante spanning op: Spec-Driven Development lijkt terug te gaan naar meer upfront design, terwijl de agile beweging decennialang heeft benadrukt dat Big Design Up Front (BDUF) problematisch is. Simon Brown’s presentatie The Lost Art of Software Design (2022) legt de nuance uit: het probleem was nooit design zelf, maar te veel design van tevoren. Zijn mantra: “Just Enough Up-Front Design” — genoeg om richting te geven, niet zoveel dat je flexibiliteit verliest.
Met AI wordt deze balans anders. Een goede prompt vereist design-denken: wat wil je precies? Welke constraints? Welke edge cases? Dit is upfront design, maar in een andere vorm — je ontwerpt de specificatie, niet meteen de implementatie.
Vibe Coding voor Type 3 is de tegenpool: geen echte specificatie, geen controle, gewoon accepteren wat de AI genereert op basis van een vaag gevoel (“the vibe”). Dit is wat er gebeurt wanneer mensen zonder ervaring AI laten coderen en alles blind overnemen.
Door zelf de criteria op te geven, blijf je in Human in the Lead modus — ook al vraag je om feedback op ideeën. Het verschil met Human Curates: je geeft het kader waarbinnen de AI moet denken. Je vraagt niet “welke namen zou jij kiezen?” maar “evalueer deze namen tegen deze criteria.”
Dit is hoe je wegblijft bij AI in the Lead: door constraints te geven, zelfs als je de AI om input vraagt.
4.2 “In the Lead” betekent ook eindregie
Bij Type 1 (Human in the Lead) is de mens niet alleen de initiator — degene die begint met een duidelijk idee — maar ook de eindregisseur. De mens heeft vetorecht op alles wat de AI produceert. En dus ook de plicht om alle output te beoordelen.
Hier zit de crux van werken met AI. LLMs zijn ontzettend productief. Ze genereren in seconden wat een mens uren zou kosten. Maar die snelheid verschuift het werk: in plaats van zelf schrijven, ben je voortdurend aan het checken. De asymmetrie die ik eerder beschreef werkt hier ook: hoe meer constraints je meegeeft, hoe gerichter de output, hoe minder je hoeft te controleren.
Dit leidt tot een belangrijke vraag: hoe maak je het controleren beheersbaar?
4.3 Upskilling, reskilling en het risico op deskilling
Google hanteert voor AI-onderwijs drie begrippen: upskilling (skill-complementarity), reskilling (nieuwe rolvaardigheden aanleren) en het spiegelbeeld deskilling/downskilling (skill-substitution, verlies door afhankelijkheid) (Yang, 2026). Voor studenten betekent dit:
Upskilling: AI inzetten om concepten sneller te doorgronden, maar nog steeds zelf oefenen en toetsen zonder AI.
Reskilling: AI gebruiken om nieuwe domeinen te verkennen (bijv. data-analyse), daarna zonder AI kunnen reproduceren.
Deskilling vermijden: beginners mogen AI niet de basis laten overnemen; eerst fundamentals, daarna pas AI als versneller.
Yang (2026) koppelt dit aan Substitutive Use (voluit) versus Augmentative Use van GenAI. Substitutive Use – wat ik “AI als butler” noem – ondermijnt motivatie om nieuwe skills te leren: de tool doet het zware werk en studenten slaan cognitieve stappen over (Guo, 2024) en tonen minder exploratie (Leon, 2023). Augmentative Use – “AI als leermiddel/leraar” – vraagt juist actieve verificatie en blijft binnen reskilling/upskilling.
Kortom: voor studenten/beginners is de volgorde cruciaal. Eerst zelf leren, dan pas AI gebruiken om te versnellen, zodat we upskilling en reskilling stimuleren zonder in deskilling te vervallen.
4.4 Constraints als vangnet in de ICT
In software development hebben we technieken ontwikkeld om code controleerbaar te houden — lang voordat AI code ging genereren. Deze “Old Skool” technieken worden nu onmisbaar als vangnet voor door AI gegenereerde of te genereren code:
a) Gecompileerde talen gebruiken. Een compiler vangt fouten af voordat de code draait. TypeScript in plaats van JavaScript, C# in plaats van Python voor kritieke systemen.
b) Specifieke types maken. Object-georiënteerde (OO) of getypeerde functionele talen kun je je eigen datatypes maken (of eigenlijk meer: samenstellen uit de basistypes). Gegevenstypes om je domein te modelleren, data format voor communicatie. Bij OO koppel (idealiter) je aan dataformat zelfs direct methoden (aanroepbare functies) die dan de enige zijn deze data mogen aanpassen (encapsulatie). Hoe specifieker je types (en hoe meer encapsulatie), hoe minder ruimte voor fouten.
c) Unit tests als vangnet. Mark Seemann beschrijft in zijn blog dat unit tests zelf een cyclomatische complexiteit van 1 moeten hebben (Seemann, 2019). Simpele tests voor complexe code. Als de AI code genereert die de tests breekt, weet je dat er iets mis is — zonder elke regel te hoeven lezen.
d) Linters voor conventies. Automatische controle op codeerstijl en patronen. Een linter is een “Old Skool” vorm van AI: deterministisch, voorspelbaar, en onvermoeibaar (tokens raken niet op ;).
e) En vast nog veel meer. Code reviews, static analysis, integration tests, contract testing, logging frameworks, gradual typing… Dit is geen uitputtende lijst — er is geen kwadrant of checklist die compleetheid garandeert. Het algemene punt is: hoe meer constraints je hebt, hoe minder je handmatig hoeft te controleren.
Opmerking over het patroon “(e) En vast nog veel meer”: dit is een bewuste retorische truc, niet onwillekeurige incompleteness. Net zoals je in code altijd een else clause toevoegt (niet nóg een else if), of een default optie hebt bij een switch statement diee veel code linters afdwingen.
4.5 OO encapsulatie versus functionele immutability
Eén klassieke tegenstelling verdient aparte aandacht: Bij punt b) Object-Oriented data types komt encapsulatie, maar bij e) hadden we immutable data in functionele talen. kunnen noemen Immutable data — gegevens die je eenmaal aanmaakt maar niet wijzigt — is het functionele antwoord op “hoe maak je code controleerbaar?”
Michael Feathers (een van de grondleggers van Agile/XP) vat dit kernachtig samen in Figuur 3: OO zegt “maak je data lokaal/privaat, pas het aan via methoden” (encapsulatie = controle over wijzigingen). Functioneel programmeren zegt “maak je data onveranderbaar, dus geen wijzigingen mogelijk” (immutability).
Beide strategieën dienen hetzelfde doel: minimizing moving parts — minder plekken waar fouten kunnen ontstaan. OO doet het door wijzigingen centraal te maken; FP door ze uit te sluiten.
Figuur 3: OO en FP geven andere manieren om code begrijpelijk te maken (Feathers, z.d.).
Voor AI-gegenereerde code is dit cruciaal: hoe meer je de ruimte voor “moving parts” inperkt, hoe gerichtere output je van de AI kunt verwachten, en hoe minder handmatig reviewwerk je hebt.
De paradox: deze “Old Skool” technieken — types, encapsulatie, immutability, tests — worden juist waardevoller in het AI-tijdperk. Ze vormen het vangnet dat het mogelijk maakt om AI-productiviteit te benutten zonder de controle te verliezen.
5. Exploratieve modus: Wanneer experts als beginners leren
Tot nu toe behandelden we de types alsof ze vaste rollen zijn: Type 1 is “je rol in dit project”, Type 3 is “voorkomen op alle kosten”. Maar dit is onvolledig. Experts kunnen tijdelijk in een exploratieve modus treden — en moeten dat ook — zonder dat dit roekeloos “Vibe coding” is.
Subsecties 5.1-5.4 onderscheiden explore van exploit, beschrijven neo-Piagetiaans cyclisch leren, zien hoe experts AI leren, en geven praktische signalen voor verantwoord experimenteren.
In blog 1, sectie 4.3 beschreef ik hoe een collega-programmeur bij agentic AI op een gegeven moment “maar toestond dat de LLM vrij grote wijzigingen doorvoerde, omdat hij de vele changes ook niet meer kon overzien.” Dit is geen roekeloos gedrag — het is een moment waarop hij van expert temporair naar beginner-modus ging. Programmeren ewas bekend, en ook het domein waarin de code werkt; maar de tool: agentic AI was nieuw terrein.
In plaats van beginner-modus kan ik wellicht beter dit exploratie-modus noemen.
5.1 Explore versus Exploit
In gedrag en leren onderscheiden we twee complementaire strategieën:
Exploit: Maak gebruik van wat je al weet. Je hebt expertise in een domein, en je zet die expertise in om doelen te bereiken.
Explore: Onderzoek onbekend terrein. Je weet nog niet wat mogelijk is, dus je experimenteert.
Dit zijn geen twee aparte modi — je hebt altijd een bepaalde combinatie van beide. Je bent nooit zuiver exploit (dat zou stagnatie betekenen) of zuiver explore (dat zou inefficiëntie betekenen). In plaats daarvan: je balanceert tussen beide afhankelijk van de context. Onderzoeker Alex Hutchinson beschrijft in zijn populair wetenschappelijk boek The Explorer’s Gene hoe deze wisselwerking tussen verkenning en uitbating fundamenteel is voor leren en aanpassingsvermogen (Hutchinson, 2021).
Voor AI geldt hetzelfde. Als je een nieuw AI-model of interactiemodus leert kennen, ben je tijdelijk in exploratieve modus — zelfs als je in andere gebieden een expert bent. Je verschuift je balans.
5.2 Neo-Piagetiaans cyclisch leren
Jean Piaget beschreef hoe kinderen leren: ze gaan door stadia van sensimotor, preoperationeel, concreet-operationeel naar formeel-operationeel denken. Dit werd lange tijd gezien als lineair: stadia volgen elkaar op, je gaat niet terug.
Moderne onderwijstheorie (neo-Piagetiaans) nuanceert dit: je gaat niet lineair vooruit, maar cyclisch. Afhankelijk van de context pak je activiteiten uit verschillende stadia. Een expert in wiskunde die voor het eerst programmeren leert, gaat door soortgelijke cognitieve stadia — maar veel sneller (Chi, 2009).
Analogie naar software development: sprint-gebaseerde Agile lijkt op dit cyclische model. Je volgt niet watervalbouwstijl (plan → design → code → test → deploy, klaar). In plaats daarvan cykel je: kleine increment, test, feedback, verbeter, volgende increment. Deze cyclus herhaalt zich, en je bent constant aan het evalueren, herstellen, en bijsturen — niet alleen in uitvoering (exploit) maar ook in verkenning van wat mogelijk is (explore).
Dezelfde cyclus geldt voor leren en skill-development: je bent niet lineair “van beginner naar expert” — je bent cyclisch aan het verkennen en uitbaten binnen steeds grotere domeinen.
5.3 Experts in exploratieve modus bij AI
Dit is waar het relevant wordt voor AI-gebruik: een expert in X kan en moet in exploratieve modus gaan voor Y — vooral als Y (zoals AI) snel evolueert.
Een ervaren software engineer heeft decennia skill in “uitbaten” (exploit) — code schrijven, architecturen ontwerpen, teams leiden. Maar als die engineer met Claude Code of Cursor werkt, is hij/zij plotseling weer in exploratieve modus: “Wat kan dit model? Waar zijn zijn grenzen? Hoe verandert dit mijn workflow?”
Dit is niet hetzelfde als roekeloos “Vibe coding”. Het verschil zit in de intentie en horizon:
Exploratieve modus (positief): “Ik wil deze tool snappen, dus ik experimenteer gestructureerd. Ik let op wat werkt, wat niet, en waar mijn expertise tekortschiet. Dit is voor skill-building en tool-understanding.”
AI in the Lead / Vibe Coding (risico): “Ik laat de AI het werk doen zodat ik sneller klaar ben. Ik check niet veel, ik vertrouw de output.” Dit verschuift van exploration (leren) naar pure exploit (produceren) zonder verificatie.
Het eerste leidt tot upskilling en reskilling. Het tweede leidt tot deskilling.
Belangrijk contrast: Beginners versus Experts.
Dit onderscheid is cruciaal voor studenten. Een ervaren developer kan in één week agentic AI leren, zoals beschreven in mijn blog AI Coding Sucks. Maar een beginnende programmeur moet eerst maanden — zo niet jaren — aan Software Engineering fundamentals besteden. Data structures, algoritmen, design patterns, architectuur, debugging mindset. Dit zijn de mentale modellen waarmee je AI-output kunt beoordelen.
Daarom is de hype “spring direct op de AI-bandwagon” gevaarlijk voor beginners. Dat is pure marketing talk. Ja, AI is snel. Ja, je kunt ermee shortcuts nemen. Maar voor iemand die nog geen basis heeft, zijn shortcuts een weg naar deskilling en onbegrip. Een expert kan de exploratieve modus ingaan omdat hij/zij al een stevig fundament heeft om op terug te vallen.
Voor beginners geldt: exploratieve modus met AI-tools pas nadat je de fundamentals hebt geleerd. Niet ervoor.
5.4 Praktisch: Hoe erkent je exploratieve modus versus roekeloos?
Enkele signalen:
Exploratieve Modus
Roekeloos/Vibe Coding
Je stelt vragen: “Waarom gaf de AI dit antwoord?”
Je accepteert output zonder vraag
Je test de AI’s output actief tegen je mentale model
Je vertrouwt blind op snelheid
Je leert waar grenzen liggen, je bouwt mentale modellen
Je bouwt geen modellen op, je slooft je uit voor output
Tijdelijk (exploratie eindigt zodra je het tool snapt)
Persistent (roekeloos blijven is niet leren)
Voor skill-development, niet voor korte-termijn output
Voor korte-termijn output, ten koste van begrip
Wichtig: exploratieve modus is niet geschikt voor productiecode of kritieke projecten. Daar heb je exploit nodig: jij en je team kennen de tool, begrijpen de grenzen, en gebruiken het met constraints (zie sectie 4.3).
Maar voor onderwijs (vooral leren) is exploratieve modus essentieel. Studenten moeten tijd krijgen om AI-tools te verkennen, hun grenzen te ontdekken, en te leren waar hun eigen expertise nog nodig is. Dit is onderdeel van het cyclische leren dat neo-Piagetiaanse theorie beschrijft.
Dus ja: je kunt “Type 3-achtig” werken (veel vertrouwen op AI) zonder roekeloos te zijn, zolang je doelbewust aan het verkennen bent en niet aan het produceren zonder begrip.
6. Conclusie: Van taxonomie naar toepassing
Deze blog presenteerde een taxonomie van AI-gebruikstypes. Van Type 1 (Human in the Lead) tot Type 4 (Old Skool), met Type 3 (AI in the Lead / Vibe Coding) als waarschuwing voor blind AI-gebruik.
De kernboodschap: wie heeft de regie? Bij Type 1 en 2 blijft de mens in controle. Bij Type 3 neemt de AI over - riskant voor studenten die nog niet kunnen beoordelen of de output klopt. Type 4 (Old Skool) blijft waardevol: eerst leren zonder AI, dan pas met AI.
Figuur 4: Guitar Hero vs. echte gitaar.
Nuancering: Deze illustratie is zelf AI-gegenereerd - ironisch genoeg omdat ik niet kan tekenen. Het kostte veel prompts en lang wachten om de juiste sfeer te krijgen, en het werd nooit helemaal zoals ik wilde. Maar vergeleken met zelf tekenen was het erg veel sneller, want ik kan niet tekenen. Gitaristen gebruiken bijvoorbeeld tabs in plaats van notenbalken, maar de AI bleef notenbalk achtig iets tekenen. En het robotje die AI voor moet stellen is wat aan de infantiele kant.
Maar ik heb de plaatjes toch opgenomen. Want ik vind visuals wel erg sprekend. Zoals Google’s Technical Writing course stelt: “when it comes to reading technical material, the vast majority of adults are still little kids—still yearning for pictures rather than text” (Google, z.d.).
De analogie gaat verder dan je denkt. Net als bij gitaarspelen, waar je leert bepaalde snaren actief te dempen zodat ze niet per ongeluk klinken, moet je als developer leren bepaalde dingen niet te doen in bepaalde situaties. En net zoals stiltes en pauzes in muziek vaak tot een mooier eindresultaat leiden: less is more. Soms is de beste code, de code die je niet schrijft.
De taxonomie is geen waardeoordeel. Het beschrijft werkwijzen, geen goede of foute keuzes. Maar voor lerende studenten is niet elk type even geschikt - dat behandelt blog 3/3.
Deze blog zelf is een voorbeeld van Type 1: Human in the Lead. Ik had het onderwerp, het standpunt, de voorbeelden. De AI hielp met formuleren en structureren, maar de richting kwam van mij.
Dat geldt voor al mijn blogs. In de footer staat nu: “Ik zit in AI-gebruikstype 1” met een link naar deze pagina. Niet als disclaimer, maar als transparantie. Je weet wat je krijgt: mijn ideeën, met AI als tool.
Waarom “de eerste de beste”? Omdat Type 1 de eerste in mijn lijst is, en voor mij de beste werkwijze. Niet de enige goede — Type 2 (Human Curates) is prima voor brainstormen, Type 4 (Old Skool) blijft waardevol. Maar Type 1 is waar ik standaard wil zitten.
De titel is ook zelfspot. “De eerste de beste” klinkt als willekeurig kiezen. Maar soms is de eerste keuze ook de juiste.
Samenvatting als antwoorden op BOB-vragen ‘Oordeelsvorming’
Figuur 5: BOB-model als trechter (Schop, z.d.).
In de Oordeelsvormingsfase van het BOB-model worden vier vragen beantwoord:
Vraag
Beantwoording in deze blog
1. Wat is ons doel?
Studenten core SE skills leren ondanks de “blokkade” dat LLM’s het in het begin beter kunnen - Plus AI/prompting skills en kennis bijbrengen → Sectie 4.2-4.3 (constraints)
2. Waar maken we ons zorgen over?
Geen studentenaanwas meer - Studenten leren SE skills niet omdat ze AI als butler gebruiken zonder begrip → Sectie 3 (AI in the Lead / Vibe Coding)
3. Wat zou die zorgen verminderen?
Werkveld geeft aan dat SE skills nodig blijven - Autoritatieve bronnen bevestigen dit (Google, podcasts) - Studenten kunnen laten zien dat ze met “AI als leraar” én eigen eindregie kunnen werken → Sectie 1-2, 4c (Learned from AI)
4. Aan welke voorwaarden moet het besluit voldoen?
HAN-thema’s (Slim, Schoon, Sociaal) - Onderwijs moet aantrekkelijk zijn voor studenten - Ruimte voor keuzevakken en flexibilisering - Aandacht voor ethiek en toekomstgericht organiseren → Sectie 4.3 (vangnet technieken)
Bronnen
Barthes, R. (1967). The Death of the Author. Aspen, 5-6. Geraadpleegd op 10 januari 2026 van https://en.wikipedia.org/wiki/The_Death_of_the_Author
Brooks, F. P. (1975). The Mythical Man-Month: Essays on Software Engineering. Addison-Wesley.
Brown, S. (2022). The Lost Art of Software Design [Presentatie]. Geraadpleegd op 13 januari 2026 van https://static.simonbrown.je/the-lost-art-of-software-design.pdf
Chi, M. T. H. (2009). Active-Constructive-Interactive: A Conceptual Framework for Differentiating Learning Activities. Topics in Cognitive Science, 1(1), 73-105. Geraadpleegd op 21 januari 2026 van https://onlinelibrary.wiley.com/doi/10.1111/j.1756-8765.2008.01005.x
Guo, X., et al. (2024). Student motivation and substitutive GenAI use. Journal of EdTech Studies. Geraadpleegd op 21 januari 2026.
Harrer, S., & Ford, N. (oktober 2024). Specification-Driven Development with GenAI Tools. Martin Fowler. Geraadpleegd op 13 januari 2026 van https://martinfowler.com/articles/exploring-gen-ai/sdd-3-tools.html
Hashicorp. (2025). Kiro: Agentic IDE for Spec-Driven Development. Geraadpleegd van https://kiro.dev/
Hutchinson, A. (2021). The Explorer’s Gene: Why Some of Us Wander and Others Stay Home. Simon & Schuster. Geraadpleegd op 21 januari 2026.
Kahneman, D. (2011). Thinking, Fast and Slow. Farrar, Straus and Giroux. Geraadpleegd op 10 januari 2026 van https://en.wikipedia.org/wiki/Thinking,_Fast_and_Slow
Leon, M. (2023). Exploratory behavior and AI tools in learning. Learning Sciences Review. Geraadpleegd op 21 januari 2026.
Minto, B. (1987). The Pyramid Principle: Logic in Writing and Thinking. Financial Times Prentice Hall.
Reddit. (2022, maart 7). To remember how many feet there are in a mile, u just gotta use 5 tomatoes… r/ShitAmericansSay. Geraadpleegd op 15 januari 2026 van https://www.reddit.com/r/ShitAmericansSay/comments/t8knwd/to_remember_how_many_feet_there_are_in_a_mile_u/
Schop, G. J. (z.d.). BOB-model. Managementmodellensite. Geraadpleegd op 20 januari 2026 van https://managementmodellensite.nl/bob-model/
Seemann, M. (9 december 2019). Put cyclomatic complexity to good use. Geraadpleegd op 10 januari 2026 van https://blog.ploeh.dk/2019/12/09/put-cyclomatic-complexity-to-good-use/
Wikipedia. (2024). Rubber duck debugging. Geraadpleegd op 20 januari 2026 van https://en.wikipedia.org/wiki/Rubber_duck_debugging
Wikipedia. (2024). Taxonomy. Geraadpleegd op 20 januari 2026 van https://en.wikipedia.org/wiki/Taxonomy
Yang, B., et al. (april 2026). Generative AI and student skill dynamics. Information & Management. Geraadpleegd op 21 januari 2026 van https://www.sciencedirect.com/science/article/pii/S0268401225001343
Bart van der Wal
Docent aan de HAN University of Applied Sciences en MAMIL met een passie voor SwimRun en andere avontuurlijke duursportavonturen. Schrijft over technologie, softwareontwikkeling en duursport.

 Figuur 1: De vier types AI-gebruik (met Type 4 opgesplitst in drie varianten): van menselijk idee met AI-generatie tot mens zonder AI
Figuur 1: De vier types AI-gebruik (met Type 4 opgesplitst in drie varianten): van menselijk idee met AI-generatie tot mens zonder AI Figuur 2: “Create apps without knowing how to code” klinkt verleidelijk, maar levert geen begrip op
Figuur 2: “Create apps without knowing how to code” klinkt verleidelijk, maar levert geen begrip op Figuur 3: De vier AI-gebruikstypes in een kwadrant
Figuur 3: De vier AI-gebruikstypes in een kwadrant Figuur 4: Prompt/answer length asymmetry
Figuur 4: Prompt/answer length asymmetry Figuur 5: “5 tomatoes” (five-two-eight-oh) om 5280 feet in a mile te onthouden vs. 1 km = 1000 m
Figuur 5: “5 tomatoes” (five-two-eight-oh) om 5280 feet in a mile te onthouden vs. 1 km = 1000 m Figuur 3: OO en FP geven andere manieren om code begrijpelijk te maken (Feathers, z.d.).
Figuur 3: OO en FP geven andere manieren om code begrijpelijk te maken (Feathers, z.d.). Figuur 4: Guitar Hero vs. echte gitaar.
Figuur 4: Guitar Hero vs. echte gitaar.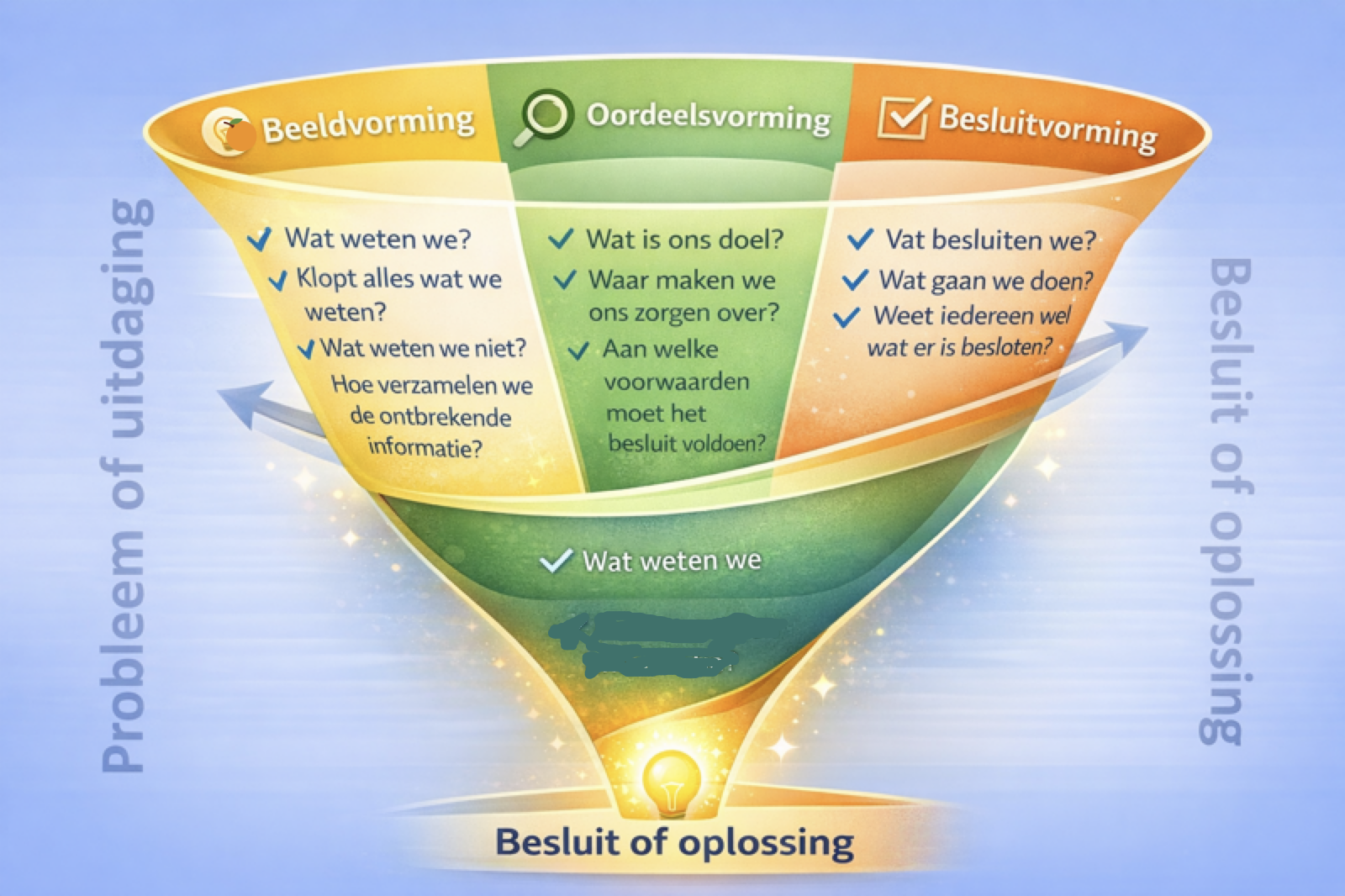 Figuur 5: BOB-model als trechter (Schop, z.d.).
Figuur 5: BOB-model als trechter (Schop, z.d.).