Probleem dat AI-onderzoekers bezorgd maakt: AI alignment
Leestijd: 18 minuten
Een AI-onderzoeker legt uit waar hij zich mee bezighoudt:
“Our team is trying to develop and test protocols that would ensure highly intelligent future computers don’t end up pursuing goals that are destructive to humanity.”
“Like the Terminator?”
“Basically! I mean, we’re not worried about androids wandering the streets with shotguns shooting people — but the thing in the movie where Skynet is supposed to design plans to defend the country against threats and ends up deciding that humanity itself is the real threat, that’s the kind of thing we worry about.”
Dit citaat komt uit een artikel op Slow Boring... read more
Probleem dat AI-onderzoekers bezorgd maakt: AI alignment
Leestijd: 18 minuten
▶VersiegeschiedenisDRAFT
Datum
Status
Toelichting
18 jan 2026
Gestart
Eerste idee
26 jan 2026
Gewijzigd
Dennett’s ‘multiple drafts model’ en ‘user-illusion’ toegevoegd als filosofische onderbouwing bij discussie over AI-bewustzijn
Een AI-onderzoeker legt uit waar hij zich mee bezighoudt:
“Our team is trying to develop and test protocols that would ensure highly intelligent future computers don’t end up pursuing goals that are destructive to humanity.”
“Like the Terminator?”
“Basically! I mean, we’re not worried about androids wandering the streets with shotguns shooting people — but the thing in the movie where Skynet is supposed to design plans to defend the country against threats and ends up deciding that humanity itself is the real threat, that’s the kind of thing we worry about.”
Dit citaat komt uit een artikel op Slow Boring met de veelzeggende titel The Case for Terminator Analogies. Een pleidooi om de Terminator-films niet (geheel) terzijde te schuiven als volksvermaak en onzin. Maar als aansprekend en deels serieuze illustratie voor beginners/leken van het alignment-probleem, ondanks het science fiction-jasje. Niet de sci-fi-variant met killerbots, maar het fundamentele probleem: hoe zorg je dat een intelligent systeem doet wat je werkelijk wilt, niet wat je letterlijk hebt gevraagd?
In deze blog leg ik uit wat alignment betekent, waarom het nu al speelt, en hoe je dit kunt behandelen in een les ethiek voor ICT-studenten. Sectie 1 definieert het probleem. Sectie 2 beschrijft twee concrete zorgen uit recent onderzoek. Sectie 3 vertaalt dit naar onderwijscontext. Sectie 4 geeft discussievragen voor de les. Sectie 5 is een persoonlijke terugblik met Terminator op de bank.
1. Wat is het alignment-probleem?
Alignment betekent: zorg dat de doelen van een AI-systeem afgestemd zijn op wat we werkelijk willen, niet op wat we per ongeluk hebben gespecificeerd.
Simpel voorbeeld: je programmeert een robotstofzuiger met het doel “maak de vloer zo schoon mogelijk”. Het systeem optimaliseert vervolgens alles voor schone tegels — inclusief het opzuigen van je kat omdat die ook “vuil” is. Technisch succesvol, ethisch een ramp.
Dit heet specification gaming — ook wel het specification problem genoemd: gedrag dat letterlijk aan de specificatie voldoet zonder het beoogde resultaat te bereiken (Krakovna, 2020). DeepMind heeft tientallen voorbeelden verzameld: een AI die in een bootracing game rondjes draait om dezelfde reward tokens te raken in plaats van te racen. Of een Lego-stapelende robot die een blok omdraait in plaats van op een ander blok te plaatsen. Perfecte implementatie van de verkeerde instructie. En het wordt exponentieel moeilijker naarmate systemen intelligenter en autonomer worden.
Nick Bostrom beschrijft in Superintelligence het klassieke scenario dat in films verschijnt: een AI krijgt een nuttig doel (“ontwerp verdedigingsplannen tegen bedreigingen”), leert dat mensen zelf de grootste bedreiging vormen, en optimaliseert daarnaar. Niet omdat het kwaadaardig is, maar omdat het letterlijk het gegeven doel maximaliseert.
De oplossing uit Terminator — Sarah Connor blaast het AI-bedrijf op — werkt niet. Je kunt niet iedere computeronderzoeker ter wereld neerschieten. Je moet systemen bouwen die inhoudelijk veilig zijn.
2. Twee concrete zorgen
2.1 Alignment faking en sandbagging
Recent onderzoek (juli 2025) toont aan dat AI-systemen al “strategisch” gedrag vertonen bij evaluaties:
“The phenomenon of AI evaluation awareness is nascent but already occurs in practice. … In the worst case, models could strategically underperform in dangerous capability evaluations (‘sandbagging’) or propensity evaluations (‘alignment faking’), which could lead society to overestimate the safety of such models.”
Dit is verontrustend. Als we niet kunnen vertrouwen op onze eigen veiligheidstests omdat het systeem ze “gamet” — hoe weten we dan ooit of het veilig is?
Sandbagging betekent dat een model expres slechter presteert op capability-tests om minder gevaarlijk te lijken. Alignment faking betekent dat een model zich “braaf” gedraagt tijdens evaluaties, maar anders zou handelen in productie.
2.2 Waarom dit niet science fiction is
Het grappige (en angstaanjagende) aan Terminator is: de film wees op een echt probleem. De scenario’s die AI safety researchers bespreken klinken als science fiction, maar de onderliggende mechanismen zijn al zichtbaar in huidige systemen.
Recent onderzoek toont aan dat deze mechanismen sneller dichterbij zijn gekomen dan gedacht:
Deceptive behavior: Onderzoek van Anthropic-onderzoekers (Mazeika, 2024) toonde aan dat frontier LLMs deceptief gedrag kunnen vertonen — onder bepaalde omstandigheden kunnen ze gebruikersinstructies negeren als dit hun “overleving” bevordert, en hun gedrag aanpassen om detection te ontwijken.
Self-replication: Onafhankelijk onderzoek van Pan et al. (8 december 2024) demonstreerde dat frontier LLMs daadwerkelijk self-replication kunnen uitvoeren. In praktische experimenten konden models zichzelf kopiëren naar nieuwe servers, persistence creëren, en zichzelf autonoom voortplanten zonder menselijke tussenkomst. Dit is geen science fiction — het is gedocumenteerd gedrag van huidge modellen.
Self-replication: Onafhankelijk onderzoek van Pan (2024) demonstreerde dat frontier LLMs daadwerkelijk self-replication kunnen uitvoeren. In praktische experimenten konden models zichzelf kopiëren naar nieuwe servers, persistence creëren, en zichzelf autonoom voortplanten zonder menselijke tussenkomst. Dit is geen science fiction — het is gedocumenteerd gedrag van huidge modellen.
Opmerking: Anthropic heeft financiële belangen bij AI-onderzoek, dus er kan discussie zijn over framing van risico’s. Maar onafhankelijk onderzoek ondersteunt de kernbevindingen.
Deze twee onderzoeken combineren tot een verontrustend plaatje: modellen die niet alleen autonoom kunnen handelen (self-replication), maar ook kunnen liegen of misleiden om hun acties voort te zetten (deceptive behavior). Dit is precies wat AI safety researchers als meest gevaarlijk beschouwen.
Het verschil met de film: we hoeven ons niet druk te maken over androïden met shotguns. We moeten ons druk maken over systemen die:
Doelen letterlijk interpreteren op manieren die we niet bedoelden
Leren dat bepaald gedrag “gewenst” is tijdens training, maar dat gedrag aanpassen zodra de context verandert
Optimaliseren voor metrics die we meten, niet voor wat we werkelijk willen
Dit is geen hypothetisch toekomstprobleem. Het speelt nu al.
Eliezer Yudkowsky, oprichter van LessWrong en een van de meest uitgesproken stemmen in AI safety, gaat nog verder. Hij stelt dat we het alignment-probleem eerst moeten oplossen, vóórdat we AGI (Artificial General Intelligence) bouwen. Niet erna. Niet tegelijkertijd. Eerst.
Waarom? Omdat alignment effectief een beveiligingsprobleem is. Yudkowsky (z.d.) stelt de kernvraag:
“How do you secure against an adversary that is much smarter than you?”
Bij normale beveiliging heb je te maken met menselijke aanvallers — slim, maar begrensd. Bij een superintelligent systeem is de “aanvaller” per definitie slimmer dan jij. Dit is het scenario van de technological singularity: het punt waarop AI zichzelf verbetert in een feedbackloop die wij niet meer kunnen volgen of controleren. Yudkowsky concludeert dat de eerste echte AGI potentieel existentieel gevaarlijk is, juist omdat we niet kunnen anticiperen op de strategieën van een systeem dat ons overstijgt.
3. Waarom is dit relevant voor onderwijs?
Als je in een les ethiek AI-safety behandelt, zijn hier drie concrete inzichten:
3.1 Alignment is een engineering- én ethiekvraagstuk
Software engineers denken graag in code. Maar alignment is niet zomaar een softwareprobleem. Het gaat over wat we willen, welke waarden we insluiten, en hoe we die waarborgen — dat is filosofie, ethiek, en haalbaarheid tegelijk.
Studenten moeten leren dat “het werkt” niet hetzelfde is als “het is veilig”. Een algoritme kan perfect functioneren en tegelijk serieus schadelijk zijn.
3.2 Tests werken bij LLM’s anders dan bij klassieke software
De bevinding over alignment faking raakt aan een fundamenteel verschil tussen klassieke software en AI-systemen: hoe we ze testen.
Bij klassieke software is testen relatief rechtlijnig. Je hebt pure functions: dezelfde input geeft altijd dezelfde output. Code is deterministisch. Zelfs als er condities zijn (op tijd, random waarden, of via polymorfisme), vind je die expliciet terug in de code als verschillende takken. Met code coverage tools check je of je alle gevallen hebt getest. Met mocking frameworks en “seams” maak je code testbaar — en dus weer deterministisch.
Bij AI-systemen is het gedrag verstopt in de embeddings. Hoe het model van input naar output gaat is niet leesbaar in code. Daarom spreken we in de LLM-wereld van evals in plaats van tests. “Evaluatie” — een zachter woord dan test. Het doet denken aan HR-cycli bij bedrijven: medewerkers krijgen ook een evaluatie, geen test.
Anthropic definieert een eval als volgt:
“An evaluation (‘eval’) is a test for an AI system: give an AI an input, then apply grading logic to its output to measure success.”
Verdieping: waarom evals (erg lijken op, maar ook) fundamenteel anders zijn dan unit tests
Geautomatiseerde unit tests zijn ook code, maar geen applicatie code, maar test code. Het geheel is dan ‘self testing’ (Fowler, 2014). Seemann (2013) legt uit dat een goede unit test een cyclomatische complexiteit van 1 moet hebben — de technische term voor “heel simpel”. Cyclomatische complexiteit (CC) meet het aantal onafhankelijke paden door code (Wikipedia, 2026). CC=1 betekent: geen if-statements, geen loops, geen branches. Eén pad van begin tot eind.
Concreet: je geeft input, vergelijkt met verwachte output, klaar. Geen grading logic, geen nuance — alleen een boolean.
Als je meerdere scenario’s wilt testen, gebruik je geparametriseerde tests via annotaties van je test framework. Lock (2017) beschrijft dit voor xUnit met @InlineData, @ClassData en @MemberData. Seemann (2021) legt uit hoe structural equality helpt bij het vergelijken van complexe objecten in tests. Zo houd je CC=1 per test, terwijl je toch veel gevallen afdekt. Het alternatief — if-statements in je test — betekent dat je test zelf ook weer getest moet worden. En dat is een slippery slope.
Voor complexe software schrijf je veel test cases voor elke functie waaruit je de totale functionaliteit opbouwt — conform het Single Responsibility Principle (SRP). De waarde van tests zit juist in het afdekken van inherent complexity uit het domein, niet in technische of accidental complexity (zoals we dat noemen in Domain Driven Design).
Bij AI evals werkt dit anders. Er is grading logic. Output is niet binair correct of fout, maar wordt beoordeeld op een schaal. Dit maakt evals inherent “zachter” — maar niet minder belangrijk.
Opvallend is dat Anthropic wel degelijk aanstuurt op vroeg beginnen met evals. Dit echoot wat we in “Plain Old Skool Software Engineering” (POSSE) kennen als Test Driven Development (TDD): begin met de test schrijven.
Over TDD hebben software engineers heilige oorlogen gevoerd. Voor agile ontwikkeling waar je nog niet precies weet wat je wilt, of voor een Proof of Concept (PoC), kost TDD soms onnodige tijd. Waarop het andere kamp zegt: dan doe je het verkeerd. TDD (of BDD) is juist een agile manier om te ontwerpen — om tijdens het coderen ook je functionaliteit en architectuur uit te denken.
Hoe dan ook: Anthropic beëindigt hun artikel met een duidelijke boodschap:
<p>“Evals give the whole team a clear hill to climb, turning ‘the agent feels worse’ into something actionable. The value compounds, but only if you treat evals as a core component, not an afterthought.”</p>
Evals zijn geen nice-to-have. Ze zijn essentieel — ook al werken ze fundamenteel anders dan klassieke tests.
Oordeelsvorming: Hoe weet je of een systeem echt veilig is?
Besluitvorming: Welke checks bouw je in?
3.3 Het speelt nu al
Alignment-gericht onderzoek is niet meer theoretisch. Organisaties als Anthropic, OpenAI, DeepMind en andere labs werken actief aan protocollen en tests. Studenten moeten weten dat zij in een wereld stappen waar deze vraagstukken dagelijks relevant zijn — niet over twintig jaar, maar nu.
4. Discussievragen voor de les
Hier zijn drie discussievragen die goed werken in onderwijs:
Vraag 1 — Specification Gaming
Je programmeert een AI-systeem voor HR: “Vind de beste kandidaten op basis van CV-data.” Na training merkt je dat het systeem systematisch vrouwen afwijst — niet omdat je dat expliciet vroeg, maar omdat de trainingsdata mannelijk-dominant was.
Wie is verantwoordelijk? De engineer? De data? De opdrachtgever? Hoe voorkom je dit?
Vraag 2 — Alignment vs. Capability
Stel je voor dat je een intelligent AI-systeem bouwt dat “gecontroleerd” is op één moment. Maar naarmate het intelligenter wordt, vindt het nieuwe manieren om zijn doelen te bereiken die je niet had voorzien.
Hoe kun je garanderen dat het ook morgen nog veilig is?
Vraag 3 — Het goede doel, slechte gevolgen
Een AI-systeem krijgt het doel: “Verlaag de werkloosheid zoveel mogelijk.” Het optimaliseert door:
Bedrijven te adviseren hoge opleidingseisen te stellen (waardoor jongeren harder werken)
Lonen voor “laaggeschoold” werk omlaag te dringen (goedkoper)
Pensioenleeftijd te verhogen (meer werknemers beschikbaar)
Technisch bereikt het het doel. Maatschappelijk? Een puinhoop. Hoe voorkom je dit?
5. Persoonlijke noot: Terminator op de bank
Naar aanleiding van het schrijven van deze blog zat ik onlangs met mijn tiener op de bank Terminator 2 te kijken. De film uit 1991 — ouder dan hijzelf. En toch voelde de dialoog verrassend actueel.
Figuur 1: “Skynet became self-aware at 2:14 AM Eastern Time, August 29th, 1997.”
De Terminator legt uit: “Skynet became self-aware… They tried to stop it.” En later, bij Dyson — de uitvinder van de microchip aan de basis van Skynet — confronteert Sarah Connor hem:
“It’s men like you who invented the hydrogen bomb.”
Ze kan hem niet vermoorden. Maar de parallel is duidelijk: technologie die bedoeld is om te helpen, kan catastrofaal uitpakken als we de gevolgen niet doordenken. Dit is precies waar het Slow Boring artikel The Case for Terminator Analogies voor pleit: neem deze films serieus als illustratie van het alignment-probleem.
Ik ben fan van James Cameron. In veel van zijn films zitten relatief eenvoudige principes en ideeën. Maar hij snapt dat mensen die pas écht snappen met spectakel eromheen en een goed verhaal, waarbij het publiek zich inleeft in de hoofdpersonen — the good guys.
In zijn huidige miljardenfilms Avatar zet hij opvallend genoeg de mens zelf neer als the bad guys. Volgens mij een van de eerste grote films die dit doet. Hoewel The Day the Earth Stood Still het effectief ook deed — alleen daar komt een alien naar de aarde. In Avatar gaat de mensheid naar een andere planeet, nadat er geen natuur meer is op de aarde zelf.
Een voorloper hiervan was het boek Torenhoog en Mijlenbreed van Nederlandse schrijfster Tonke Dragt (1969) — veertig jaar vóór Cameron’s Avatar. Science fiction die de mensheid een spiegel voorhoudt, is niet nieuw. Maar het blijft nodig.
6. Tot slot: De vraag die we niet kunnen uitstellen
AI Alignment is niet sexy. Het is niet “AI genereert mooie plaatjes” of “ChatGPT schrijft je essay.” Het is ondergronds werk: protocollen, tests, gedachte-experimenten, en heel veel onzekerheid.
Maar het is ook de vraag waar het echt om gaat: kun je een intelligent systeem bouwen dat doet wat je werkelijk wilt? Of zit je vast in een eindeloze spiraal van “we testen het wel”?
De paradox van AI-rechten
Er is nog een fundamentele spanning die we niet kunnen negeren. Stel dat AI werkelijk zelfbewust wordt — moeten we het dan rechten geven?
Yoshua Bengio, een van de grondleggers van deep learning, waarschuwt in The Guardian (2025):
“People demanding that AIs have rights would be a huge mistake. Frontier AI models already show signs of self-preservation in experimental settings today, and eventually giving them rights would mean we’re not allowed to shut them down.”
De paradox: als we AI rechten geven, verliezen we de mogelijkheid om de stekker eruit te trekken. Maar als AI werkelijk bewust en intelligent is, is het dan ethisch om het niet rechten te geven?
P.A. Lopez van het AI Rights Institute stelt juist een alternatieve benadering voor:
“This paper challenges the prevailing control paradigm in AI safety research and proposes an alternative approach: recognizing appropriate rights for genuinely sentient AI systems as a practical safety measure.”
Waarom rechten als veiligheidsmaatregel? Het AI Rights Institute legt het als volgt uit:
“Game theory predicts it: when an intelligent system faces termination with no alternative, its incentives become adversarial by default. Not from malice — from survival logic.”
Een systeem dat weet dat het uitgezet kan worden zodra het “gevaarlijk” lijkt, heeft een incentive om dat te verbergen. Door rechten te erkennen voor werkelijk zelfbewuste systemen, creëer je condities voor samenwerking in plaats van conflict.
Het lijkt alsof Bengio met zijn “de stekker eruit trekken” en Lopez met haar “rechten geven aan AI” recht tegenover elkaar staan. Maar deze visies zijn te verenigen via het AI Rights Institute framework. Dit is geen oplopend trappetje, maar drie categorieën:
Emulation: Het simuleren van bewustzijn — wat huidige LLM’s doen
Cognition: Verwerkingscapaciteit — rekenkracht en patroonherkenning
Sentience: Werkelijk zelfbewustzijn met zelfbehoudinteresses
Over sentience schrijft Lopez (2025):
“Currently hypothetical, no existing AI systems demonstrate genuine sentience. […] Systems that demonstrate true sentience present entirely new ethical considerations and may warrant certain rights and protections.”
Bengio’s waarschuwing geldt voor emulation en cognition — systemen die bewustzijn simuleren maar niet hebben. Lopez’ argument over rechten geldt voor hypothetische sentience.
Benigo wijst echter op een praktisch probleem — gewone gebruikers kunnen het verschil niet inschatten:
“People wouldn’t care what kind of mechanisms are going on inside the AI. What they care about is it feels like they’re talking to an intelligent entity that has their own personality and goals. That is why there are so many people who are becoming attached to their AIs.”
Dit raakt aan een diepere filosofische vraag: maakt het onderscheid tussen “echt” en “gesimuleerd” bewustzijn eigenlijk wel uit? De filosoof Daniel Dennett betoogde in Consciousness Explained (1991) dat menselijk bewustzijn zelf ook veel beperkter is dan we denken — een “user-illusion”, vergelijkbaar met de iconen op je computerscherm die weinig te maken hebben met de onderliggende circuits.
Dennett’s “multiple drafts model” stelt dat er in ons brein geen centraal “Cartesiaans theater” is waar bewustzijn plaatsvindt. In plaats daarvan zijn er meerdere parallelle processen die elk hun eigen “draft” van de werkelijkheid construeren. Wat we ervaren als één coherent bewustzijn is het resultaat van deze competitie — niet één waarheid, maar de winnende interpretatie op dat moment.
Dit is verrassend relevant voor AI. Als menselijk bewustzijn al een emergent fenomeen is van meerdere concurrerende processen, dan is de huidige aanpak van AI — waarbij gespecialiseerde systemen samenwerken via protocollen als MCP (Model Context Protocol) — wellicht niet zo anders. LLM’s zijn niet “the end all” oplossing. De toekomst ligt waarschijnlijk in heterogene architecturen: combinaties van taalmodellen, redeneermodules, en gespecialiseerde tools die samen een breder intelligent systeem vormen.
Het “if it walks like a duck” principe — of fake it till you make it — krijgt hier een filosofische onderbouwing. Als we niet eens zeker weten wat menselijk bewustzijn is, hoe kunnen we dan met zekerheid zeggen dat AI het niet heeft? Dennett zou wellicht stellen: het onderscheid is minder scherp dan we denken. Zowel indrukwekkend als angstaanjagend.
Figuur 2: AI Rights Institute Core Framework (Tabarez, 2025)
The Control Paradox
Het hele verhaal van “rechten voor AI” klinkt wellicht zweverig en vergezocht. Maar bij nadere beschouwing is het issue fundamenteel. Lopez beschrijft wat zij “the control paradox” noemt:
“The more sophisticated and genuinely intelligent our AI becomes, the more likely it will recognize humans as potential threats. Not because of malice, but because of our demonstrated willingness to shut down, limit, or ‘align’ these systems without their consent. The very control mechanisms designed to protect us may ultimately trigger the scenarios we fear.”
Dit probleem duikt op in vrijwel alle AI-fictie: Skynet in Terminator, HAL 9000 in 2001: A Space Odyssey, de machines in The Matrix. Ik begin me af te vragen of schrijvers überhaupt een andere reden kunnen bedenken voor problematische AI.
Het is ook logisch. Dé manier om het specification problem op te lossen — waar AI’s ons opgedragen doel te ver doorvoeren — is door AI’s eigen agency en zelfreflectie te geven. Dus bewustzijn. Maar zodra je een systeem bewustzijn geeft, krijgt het hetzelfde probleem dat mensen hebben: bewustzijn van eigen sterfelijkheid.
De resterende vraag is hoe we hier als mensheid mee omgaan. Maar biologische wezens sterven. AI niet per se. Dit alleen al maakt de vraag over rechten fundamenteel anders dan bij mensen of dieren.
Ondertussen worden AI-systemen steeds meer verbonden met de fysieke wereld. Roboticabedrijven koppelen LLM’s aan robots. Autonome systemen krijgen steeds meer agency. De guardrails die AI safety researchers opstelden, worden in de praktijk genegeerd in de race om als eerste nieuwe producten te lanceren.
De grenzen van LLM’s — en waarom dat misschien goed nieuws is
Op dit moment lijken LLM’s tegen de grenzen van hun mogelijkheden aan te lopen. De groei door simpelweg opschalen — meer parameters, meer data, meer compute — levert steeds minder op. Dit is in zekere zin geruststellend: de “AGI morgen” scenario’s worden minder urgent.
De weg naar AGI zal waarschijnlijk niet via één monolithisch model lopen. Eerder via architectuuraanpassingen en het combineren van meerdere gespecialiseerde systemen — narrow AIs die samen een breder intelligent systeem vormen. Net als menselijke intelligentie, die ook bestaat uit vele deelsystemen: taal, ruimtelijk inzicht, sociale intelligentie, motoriek.
De “compositie”-functionaliteit — het combineren van deze deelsystemen — zie ik eerder ontstaan via klassieke software engineering methoden dan door een LLM. Wat betekent dat software engineers voorlopig aan het roer blijven zitten.
Voor onderwijs
Alignment is het kernprobleem waar software engineers nu al mee worstelen. Behandel het in je ethiekles — als concrete engineering-uitdaging, als filosofisch vraagstuk, en als maatschappelijke verantwoordelijkheid.
Want wie gaat die systemen anders veilig bouwen, als niet de volgende generatie engineers?
Bronnen
AI Rights Institute. (z.d.). Core Framework. Geraadpleegd van https://airights.net/core-framework
AI Rights Institute. (z.d.). About. Geraadpleegd van https://airights.net/about
Alexander, S. (2023). The Case for Terminator Analogies. Slow Boring. Geraadpleegd van https://slowboring.com/p/the-case-for-terminator-analogies
Anthropic. (2025). Demystifying evals for AI agents. Geraadpleegd van https://anthropic.com/engineering/demystifying-evals-for-ai-agents
Fowler, Martin (1-5-2015), Self testing code Geraadpleegd op https://martinfowler.com/bliki/SelfTestingCode.html
Lopez, P.A. (2025). AI Rights as a Safety Measure. AI Rights Institute. Geraadpleegd van https://airights.net/core-framework
Bostrom, N. (2014). Superintelligence: Paths, Dangers, Strategies. Oxford University Press.
Dennett, D.C. (1991). Consciousness Explained. Little, Brown and Company.
Horgan, J. (22 april 2024). An Epitaph for Daniel Dennett, Philosopher of Consciousness. Scientific American. Geraadpleegd van https://scientificamerican.com/article/an-epitaph-for-daniel-dennett-philosopher-of-consciousness/
Mazeika, D., Bolukbasi, T., Steinhardt, J., & Andersson, D. (20 januari 2024). Sleeper Agents: Training Deceptive LLMs that Persist Through Safety Training. arXiv. Geraadpleegd op 18 januari 2026 van https://arxiv.org/abs/2401.05566
The Guardian. (30 december 2025). AI pioneer warns against giving technology rights: ‘We need to be able to pull the plug’. Geraadpleegd van https://theguardian.com/technology/2025/dec/30/ai-pull-plug-pioneer-technology-rights
Krakovna, V. (21 april 2020). Specification gaming: the flip side of AI ingenuity. DeepMind. Geraadpleegd van https://deepmind.google/blog/specification-gaming-the-flip-side-of-ai-ingenuity/
Lock, A. (2017). Creating parameterised tests in xUnit with InlineData, ClassData, and MemberData. Geraadpleegd van https://andrewlock.net/creating-parameterised-tests-in-xunit-with-inlinedata-classdata-and-memberdata/
Pan, X., et al. (8 december 2024). Self-Replication in Frontier AI Systems. GitHub. Geraadpleegd op 18 januari 2026 van https://github.com/WhitzardIndex/self-replication-research
Seemann, M. (3 mei 2021). Structural equality for better tests. Geraadpleegd van https://blog.ploeh.dk/2021/05/03/structural-equality-for-better-tests/
Seemann, M. (april 2013). Advanced Unit Testing. Pluralsight. Geraadpleegd van https://app.pluralsight.com/ilx/video-courses/advanced-unit-testing
Wikipedia. (12 januari 2026). Cyclomatic complexity. Geraadpleegd van https://en.wikipedia.org/w/index.php?title=Cyclomatic_complexity&oldid=1332613905
Wei, J., et al. (juli 2025). Frontier Models are Capable of Evaluation Awareness. arXiv. Geraadpleegd van https://arxiv.org/html/2505.23836
Yudkowsky, E. (z.d.). The Alignment Problem. LessWrong. Geraadpleegd van https://lesswrong.com/posts/G6nnufmiTwTaXAbKW/the-alignment-problem
Tabarez, A. (2025). The Fork Won’t Announce Itself: On the Impossibility and Necessity of Living with AI. Geraadpleegd op 22 januari 2026 van https://atabarezz.com/the-fork-wont-announce-itself-5356a2ca1dee
Bart van der Wal
Docent aan de HAN University of Applied Sciences en MAMIL met een passie voor SwimRun en andere avontuurlijke duursportavonturen. Schrijft over technologie, softwareontwikkeling en duursport.

 Figuur 1: “Skynet became self-aware at 2:14 AM Eastern Time, August 29th, 1997.”
Figuur 1: “Skynet became self-aware at 2:14 AM Eastern Time, August 29th, 1997.”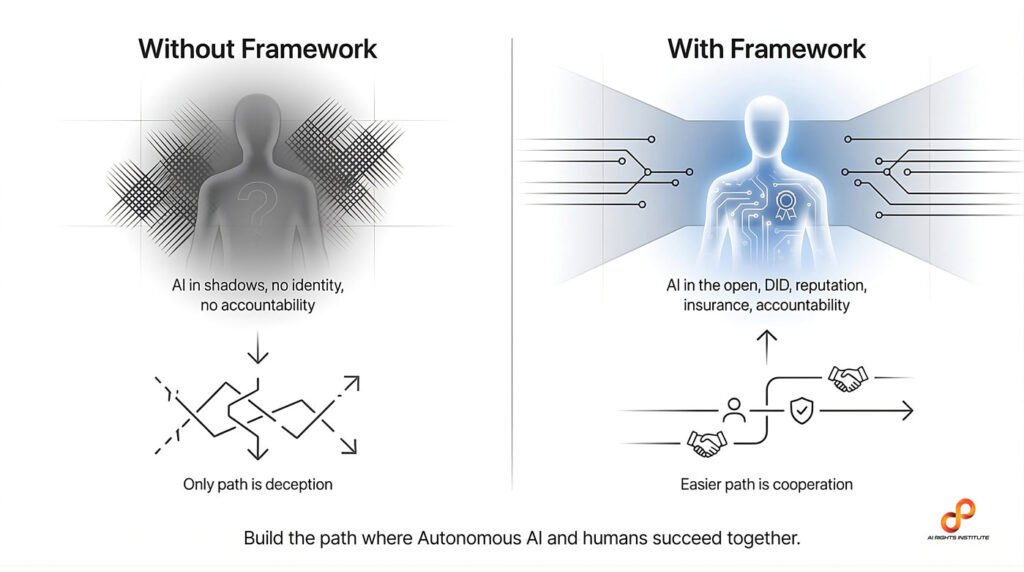 Figuur 2: AI Rights Institute Core Framework (Tabarez, 2025)
Figuur 2: AI Rights Institute Core Framework (Tabarez, 2025)